Initialization is known to be highly sensitive in Gaussian Splatting, requiring metrically accurate
Gaussians to seed a scene. We propose a novel
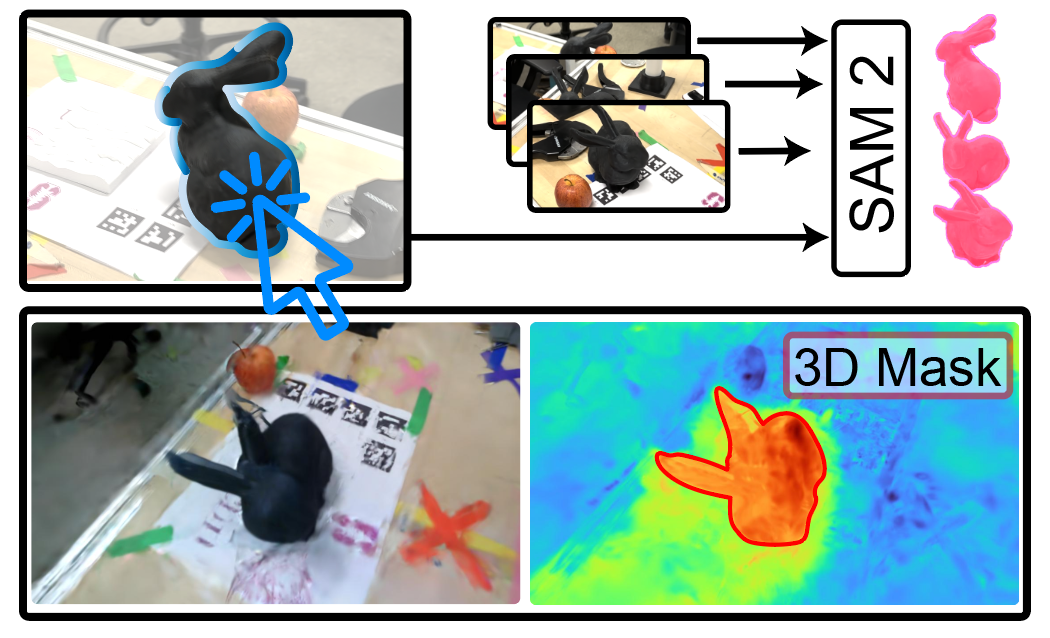
semantic depth alignment using Segment Anything 2 to align monocular depths. Concretely, we feed a color
image into a monocular depth estimator such as DepthAnythingV2. We then run the SAM2 automatic mask
generator on the RGB image, which captures objects and backgrounds in the scene.
This method does not require any depth completion networks that require extensive fine-tuning, and is a
computationally cheap step. With a depth from a depth image, often prone to noise and incorrect in
challenging lighting conditions,
we perform a mask-aware alignment on the monocular depth to output a SAM2 aligned depth; retaining the
best of both worlds: metrically accurate and geometrically precise.
The alignment is used as initialization for the scene. SAM2 aligned depths (right) improves
significantly upon a least squares alignment (left) monocular depth.